第一章 何谓Agent 为何Agent
Agent,即智能体或智能代理,是一个具有一定程度自主性的人工智能系统。更具体地说,Agent 是一个能够感知环境、做出决策并采取行动的系统。 我们倾向于把所有能够感知环境、做出决策并采取行动的实体或系统视为人工智能领域中的代理。 ChatGPT 首先通过文本或语音输出框来感知环境,并进行推理决策,之后再通过文本框或者语音与人们互动。 AlphaGo
大模型就是Agent的大脑
大模型(或称大语言模型、大型语言模型,Large Language Model,LLM)的出现标志着自主 Agent 的一大飞跃。大模型因令人印象深刻的通用推理能力而得到人们的大量关注。研究人员很快就意识到,这些大模型不仅仅是数据处理或自然语言处理领域的传统工具,它们更是推动 Agent 从静态执行者向动态决策者转变的关键。 这些基于大模型的 Agent 通过反馈学习和执行新的动作,借助庞大的参数以及大规模的语料库进行预训练,从而得到世界知识(World Knowledge)。同时,研究人员通过思维链(Chain of Thought,CoT)、ReAct(Reasoning and Acting,推理并行动)和问题分解(Problem Decomposition)等逻辑框架,引导 Agent 展现出与符号 Agent 相媲美的推理和规划能力。这些 Agent 还能够通过与环境的互动,从反馈中学习并执行新的动作,获得交互能力。
第二章 基于大模型的Agent技术框架
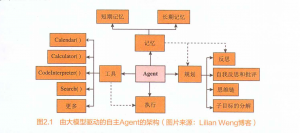
任务分解
思维链: 这是一种提示技术,通过让模型“一步一步地思考”,帮助它将大任务分解成小任务,并清楚地解释自己的思考过程。 思维树: 通过在每个步骤探索多种推理可能性,进而形成一种树状结构。思维树可以用不同的搜索方法,例如广度优先搜索(Breadth-First Search,BFS)或深度优先搜索(Depth-First Search,DFS),并通过提示或投票来评估每个步骤。
自我反思
各种记忆
预训练记忆
大模型在大量包含世界知识的数据集上进行预训练。在预训练中,大模型通过调整神经元的权重来学习理解和生成人类语言,这可以被视为其“记忆”的形成过程。通过使用深度学习神经网络和梯度下降等技术,大模型可以不断提高基于输入预测或生成文本的能力,进而形成世界知识和长期记忆。
上下文互动
大模型在执行任务时,会将长期记忆和提供的上下文(也就是提示信息)结合起来使用。理想情况下,如果上下文包含与大模型的记忆知识冲突的任务相关信息,那么大模型应优先考虑上下文,以生成更准确和具有上下文特定性的回应。通过诸如知识意识型微调(knowledge-aware fine-tuning)等方法,可以增强大模型在使用上下文和记忆知识方面的可控性和鲁棒性。
通过针对特定任务的微调进行增强
大模型可以在更具体的数据集上进一步微调,以适应特定行为或提高特定任务的性能。例如,针对 SAT(Satisfiability,可满足性)问题数据集进行微调的大模型在回答此类问题时会更加熟练。
外部记忆系统
大模型与外部记忆系统(如 Memory Bank,见图 2.3)整合,通过提供长期记忆来增强大模型性能,使大模型能够记住和回忆过去的互动、理解用户的个性并提供更个性化的互动。这涉及动态个性理解、使用双塔密集检索模型的记忆检索,以及受艾宾浩斯遗忘曲线理论启发的记忆更新机制等
ReAct
ReAct 框架的核心在于将推理和行动紧密结合起来。它不是一个简单的决策树或固定算法,而是一个综合系统,能够实时地进行信息处理、决策制定,以及行动执行。ReAct 框架的设计哲学是:在动态和不确定的环境中,有效的决策需要持续的学习和适应,以及快速将推理转化为行动的能力,即形成有效的观察—思考—行动—再观察的循环
提示工程(Prompt Engineering)
提示工程(Prompt Engineering)是一种设计和优化输入以指导大模型(如 GPT-4 模型)产生特定输出的方法。提示工程涉及创造性地构建、测试和优化用于大模型的提示。这些提示可能包括问题、陈述或指令,目的是以最有效的方式引导大模型提供所需的信息。它不仅包括文本内容的选择,还涉及格式、风格、上下文提示等方面,以激发大模型产生最佳的响应。 提示工程可以提高大模型的输出效率和准确性。通过精心设计的提示,大模型能够更快地理解问题的本质,并以更高的准确率生成有用的回答。对于特定的应用或领域,如法律、医学或工程,可以通过提示工程定制大模型的回应,使其更加相关和专业。此外,好的提示设计当然可以提升用户与 AI 的交互体验,使对话更加自然和有趣。
langchain
■ langchain-core:包含 LangChain 生态系统所需的核心抽象概念以及 LangChain 表达式语言。它是创建自定义链的基础,注重组合性。 ■ langchain-community:囊括第三方对 LangChain 各种组件的集成。这是为了将通常需要不同设置、测试实践和维护的集成代码从核心包中分离出来。 ■ langchain-experimental:包含实验性 LangChain 代码,用于研究和实验,里面的功能会经常变化。
其他认知框架
函数调用
函数调用(Function Calling)是由 OpenAI 公司提出的一种 AI 应用开发框架。在这种框架中,大模型被用作调用预定义函数的引擎。这里的预定义函数可以用于 API 调用、数据库查询或其他程序化任务。对于需要与现有系统集成或执行具体技术任务的应用,如自动化脚本或数据分析,此框架非常合适
第三章 OpenAI API、LangChain 和 LlamaIndex
都是用来开发智能体应用的框架
temperature
参数 temperature 在机器学习,特别是自然语言生成模型中非常重要,用于控制生成内容的随机性和创造性。temperature 值低时(例如 0.2),会产生更一致的输出;而 temperature 值高时(例如 1.0),会产生更加多样化和富有创造性的结果。需要根据特定应用所需的一致性和创造性来选择 temperature 值,取值范围为 0 至 2。
token
Token 直译为令牌,也可以叫子词,可被视为文本的组成部分。大模型是通过把文本拆分为一个个的 Token 来训练和推理的,因此通常用它来衡量 API 使用量。在英语中,1000 个 Token 相当于 750 个单词。
langchain
LangChain 是一个开源框架,目标是将大模型与外部数据连接起来,以便开发者能够更快和更容易地构建基于语言的 AI 应用。
LC EL
基于初心——让基于大模型的 AI 应用开发变得容易,LangChain 推出了 LangChain Expression Language(简称 LCEL )。LCEL 是一种声明式语言。它可以使 LangChain 中各组件的组合变得简单且直观。 LCEL 的特点如下。 ■ 流式处理,即在与大模型交互的过程中尽可能快地输出首个 Token,同时确保数据的连续性和不断输出,维持一个持续稳定的交互流程。 ■ 异步操作,能在同一台服务器上处理多个并发请求(这意味着相同的代码可以从原型系统直接移植到生产系统)。 ■ 自动并行执行那些可以并行的步骤,以实现尽可能低的延迟。 ■ 允许配置重试和后备选项,使链在规模上更可靠。 ■ 允许访问复杂链的中间结果,并与 LangSmith 跟踪和 LangServe 部署无缝集成。
langchang的六大模块
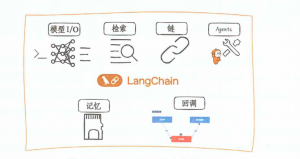 六大模块的介绍如下。
■ 模型 I/O(Model I/O):这个模块是 LangChain 与大模型的接口,负责处理输入(包含提示模板的构建)和输出数据(包含对输出数据格式的解析),以及与各种大模型的交互。
■ 检索(Retrieval):这个模块负责与程序特定的数据交互。它使 LangChain 能够从外部数据源中检索所需的信息。这些数据源包括数据库、文件系统或其他在线资源。
■ Agents:在这个模块中,LangChain 可以根据高层指令选择使用哪些工具。这些 Agent 负责决定在给定的情境下最有效的工作方式。
■ 链(Chains):这个模块包含常见的、可构建的组件,用于创建更复杂的逻辑和功能。这些链是 LangChain 处理信息和执行任务的基本构建块。
■ 记忆(Memory):记忆模块负责在链运行过程中持久化程序的状态。这使得 LangChain 能够记住先前的交互和信息,从而在多次运行中提供连续性。
■ 回调(Callbacks):这个模块负责记录和传输链的中间步骤。通过这种方式,开发者可以监控和分析 LangChain 的运行情况,以优化性能和功能。
六大模块的介绍如下。
■ 模型 I/O(Model I/O):这个模块是 LangChain 与大模型的接口,负责处理输入(包含提示模板的构建)和输出数据(包含对输出数据格式的解析),以及与各种大模型的交互。
■ 检索(Retrieval):这个模块负责与程序特定的数据交互。它使 LangChain 能够从外部数据源中检索所需的信息。这些数据源包括数据库、文件系统或其他在线资源。
■ Agents:在这个模块中,LangChain 可以根据高层指令选择使用哪些工具。这些 Agent 负责决定在给定的情境下最有效的工作方式。
■ 链(Chains):这个模块包含常见的、可构建的组件,用于创建更复杂的逻辑和功能。这些链是 LangChain 处理信息和执行任务的基本构建块。
■ 记忆(Memory):记忆模块负责在链运行过程中持久化程序的状态。这使得 LangChain 能够记住先前的交互和信息,从而在多次运行中提供连续性。
■ 回调(Callbacks):这个模块负责记录和传输链的中间步骤。通过这种方式,开发者可以监控和分析 LangChain 的运行情况,以优化性能和功能。
LangSmith
LangSmith 是 LangChain 团队推出的大模型应用(LLM App)开发与运维平台。你可以把它理解为 LLM 领域的 “应用性能监控(APM)+ 调试 IDE”,专门解决大模型应用“黑盒”难调试、难评估的问题。
Llamaindex
LlamaIndex(原 GPT Index)是一个专为 RAG(检索增强生成) 设计的数据框架。它的核心使命非常明确:解决大模型“不懂你私有数据”的痛点,将你的文档、数据库、PDF 等转化为 LLM 能理解和检索的“知识库”。 如果说 LangChain 是负责“流程编排”的项目经理,那 LlamaIndex 就是负责“数据整理与检索”的图书馆管理员。
第四章 自动化办公实现
Assistants
OpenAI 公司的 Assistants 是一种基于 GPT 模型的语言理解和生成平台。它旨在通过提供信息、解答问题、生成文本和执行特定任务来协助我们的日常工作。 嗯,听到这里,你会不会觉得 OpenAI 公司的这个 Assistants 有点 Agent 的意思。的确如此,Assistants 特意被设计为具有灵活性且功能多样,可以适用于多种场景,从简单的日常对话到复杂的技术问题解答。 Assistants 的主要特点如下。 ■ 可以理解高级语言:能够处理自然语言输入,识别用户的意图和需求。 ■ 生成丰富的文本:可以根据用户的指令生成连贯、相关且有用的文本回应。 ■ 具有适应性和可定制化:可以根据特定的应用场景和需求进行定制,以提供个性化的服务。 ■ 具有交互性:能够进行连贯的对话,理解上下文,记住对话历史,以提供更加深入和有连续性的交互体验。 ■ 易于集成:可以被集成到各种平台和应用中,如网站、应用程序或其他数字服务。
dall-e-3
DALL·E 3 是 OpenAI 推出的第三代文生图模型,也是目前 ChatGPT 生态中的默认图像生成工具。它最大的特点是“听话”——能精准理解自然语言描述,无需复杂的提示词工程就能生成细节丰富、构图准确的图片。
第五章 多功能选择的引擎——通过 Function Calling 调用函数
对于Code interpreter和File search这两个内部工具,OpenAI内部自有一套处理逻辑,用于指导Assistants判断哪些场景需要调用哪些工具。对于我们自己定制的Function,你给出的Description(说明文字)特别重要。Description就是Assistants用于判断是否应该调用这个工具的依据。
Function Calling
Function Calling 是 GPT-3.5 Turbo 和 GPT-4 等模型的新功能。这个功能允许开发者用 JSON Schema 描述函数。大模型可以智能地输出一个包含用于调用一个或多个函数的参数的 JSON 对象。 Function Calling 是连接 GPT 模型的自然语言理解能力与外部工具或 API 的桥梁,可以使从大模型中获取结构化数据或基于大模型输出触发外部动作的方式更为可靠。 Functions 调用的基本步骤如下。 1.定义函数及元数据:定义好你要做的事情的函数和元数据(JSON Schema)。把 JSON Schema 提交给大模型。 2.提出请求:告诉系统想做什么,例如查询天气信息。这个请求需要包含必要的信息,如地点。 3.模型生成命令:系统会根据用户的请求决定调用哪个功能。如果该请求与系统中的某个函数匹配,系统就会创建一个包含所有必要信息的字符串,这个字符串符合事先定义的 JSON Schema 的要求。 4.执行函数:系统首先把文本解析为 JSON 对象,然后根据这个 JSON 对象执行对应的函数。如果命令中包括地点信息,那么 JSON 对象中也会包含统一的地点信息。相应地,函数会去查找那个地点的天气信息。 5.返回结果:一旦函数执行完毕,系统会返回结果。这个结果也是用 JSON 格式来表示的。通常会把这个结果再次传递回大模型,让它生成最终的回答,也就是输出有关该地点天气信息的文本。
第六章 推理与行动的协同——通过 LangChain 中的 ReAct 框架实现自动定价
gent可以根据实时的天气和交通状况自动调整产品价格,从而优化销售策略和库存管理 首先看看这个事该怎么办(思考),其次通过搜索引擎查阅网络上今天鲜花的成本价(行动),据此我可预估鲜花的进货价格,然后根据这个价格的高低(观察)来确定要加价多少(思考),最后得出售价(行动)。
LangChain中ReAct
在 LangChain 中使用 Agent 时,我们只需要理解下面 4 个元素。 1.大模型:提供逻辑的引擎,负责生成预测和处理输入。 2.提示(prompt):负责指导模型,形成推理框架。 3.外部工具(external tools):包括数据清洗工具、搜索引擎、应用程序等。 4.Agent 执行器(Agent executor):负责调用合适的外部工具,并管理整个流程。 根据用户的输入(接收任务),Agent 会首先决定调用哪些工具,然后通过相应的工具给出答案。Agent 不仅可以同时使用多种工具,而且可以将一个工具的输出数据作为另一个工具的输入数据。
AgentExecutor的运行机制
AgentExecutor 是 Agent 的运行环境,它首先调用大模型,接收并观察结果,然后执行大模型所选择的操作,同时也负责处理多种复杂情况,包括 Agent 选择了不存在的工具的情况、工具出错的情况、Agent 产生无法解析成 Function Calling 格式的情况,以及在 Agent 决策和工具调用期间进行日志记录。
第七章 计划和执行的解耦——通过 LangChain 中的 Plan-and-Execute 实现智能调度库存
LangChain 中的 Plan-and-Execute Agent 受到关于 Plan-and-Solve 的论文的启发。LangChain 团队认为,Plan-and-Execute Agent 非常适合更复杂的长期规划,把复杂的任务拆解成一个个子任务,逐个击破。尽管这意味着会更频繁地调用大模型,但可以避免多次 ReAct Agent 循环过程中产生的提示词过长的问题。
ReAct架构的缺点
ReAct 的核心逻辑是 单步推理 → 单步执行 → 观察结果 → 循环。这种“边想边做”的模式虽然灵活,但在实际落地中暴露出三大硬伤:
- 任务跨度与上下文瓶颈 短视决策:Agent 只根据当前状态做下一步最优解,缺乏全局视野。对于需要多步铺垫的复杂任务,容易陷入局部最优,导致后续步骤无法衔接。 上下文爆炸:每一步的 Thought、Action、Observation 都会累加进上下文。任务稍长,Token 消耗就会呈线性甚至指数级增长,不仅成本高,还容易触发模型长度限制。
- 执行脆弱性与延迟 错误累积:一步出错,步步皆错。中间步骤的微小偏差(如工具调用参数错误)会导致后续推理全盘崩溃,缺乏回滚或修正机制。 高延迟:N 步任务需要发起 N 次 LLM 调用,网络往返和模型推理的耗时叠加,导致用户体验极差。
- 工具规划的局限性
工具组合爆炸:当工具库庞大时,ReAct 在每一步都面临“选择哪个工具”的难题,容易选错工具或遗漏更优的工具组合路径。
幻觉风险:模型可能会“脑补”不存在的工具或参数,导致执行失败。
Plan and Execute 架构解析
为了克服 ReAct 的“短视”问题,Plan and Execute 采用了 “先谋后动” 的二级架构:
- Planner(规划层):由 LLM 担任“总指挥”,根据目标制定详细的步骤清单(Plan)。
- Executor(执行层):由 Agent 或系统担任“执行者”,严格按步骤调用工具执行,并将结果反馈给规划层。
第8章 知识的提取与整合——通过 LlamaIndex 实现检索增强生成
检索增强生成(RAG)是一种结合信息检索和文本生成的人工智能技术。通常将它用于处理问答系统、对话生成或内容摘要等自然语言处理任务。 RAG 的优势在于它结合了检索系统的精确信息获取能力和语言模型的流畅文本生成能力。这使得 RAG 在处理复杂的语言理解任务时,能够提供更加丰富、准确的信息。例如,在问答系统中,RAG 能够提供基于具体事实的答案,而不仅限于基于语言模型的一般性推断。
RAG 中检索部分的 Pipeline 的技术实现流程
1.数据连接(data connection)和加载(load):数据多种多样,既可以是结构化的,也可以是非结构化的,通过加载过程被 RAG 读取。 2.转换(transform):在这个阶段,通过清洗、标准化和整理,把数据转换为统一的格式,以便进一步分析。 3.嵌入(embed):通过词嵌入模型,将数据转换成某种词嵌入,也就是向量的形式。 4.存储(store):将向量数据存储在某种形式的存储系统中,如内存、文件系统。更常见的存储系统是向量数据库。 5.检索(retrieve):从存储系统中检索数据,以便进一步操作。
LlamaIndex
LlamaIndex 提供了一些出色的组件来实现 RAG。这些组件可以作为构建基于 Agent 的应用的核心工具。一方面,LlamaIndex 中的某些组件具有“Agent 式”自动化决策功能,以帮助特定用例来处理数据;另一方面,LlamaIndex 也可以作为另一个 Agent 框架中的核心工具。
同样地,LangChain 也包含专门针对 Conversational Agent 和问答系统的工具,以提高性能和提升用户体验。受篇幅所限,我们没有给出 LangChain Conversational Agent 实现示例,推荐学习官方教程,看看 LangChain Conversational Agent 与 LlamaIndex 中的 ReAct RAG Agent 的异同。
第9章 GitHub 的网红聚落——AutoGPT、BabyAGI 和 CAMEL
AutoGPT
AutoGPT 是由游戏公司 Significant Gravitas 的创始人 Toran Bruce Richards 创建的一个开源的自主 AI Agent。它基于 OpenAI 公司的 GPT-4 模型,是首批将 GPT-4 模型应用于自动执行任务的应用之一。 与 ChatGPT 的单轮对话界面不同,用户只需提供一个提示或一组自然语言指令,AutoGPT 就会通过自动化多步提示过程将目标分解为子任务,并自动链接多个任务,以实现用户设定的大目标。
BabyAGI
BabyAGI 是 Yohei Nakajima 于 2023 年 3 月构思的一种具有开创性的自主任务驱动 Agent。BabyAGI 的核心理念是由 Agent 根据设定的目标生成、组织、确定优先级以及执行任务。这个 AI 驱动的任务管理系统的主要功能包括 3 部分:运用 OpenAI 公司的自然语言处理能力以及大模型的思考能力来生成、排序和执行任务;利用 Pinecone 等向量数据库引擎来存储和检索特定任务的结果,提供执行任务的相关上下文;采用 LangChain 框架进行决策。
CAMEL
CAMEL(Communicative Agents for “Mind” Exploration of Large Language Model Society)是一个由 KAUST 团队开发的开源多智能体(Multi-Agent)框架。它最核心的范式是“角色扮演”,通过让多个 AI 模拟不同角色(如程序员与产品经理)进行对话协作,来解决单智能体难以处理的复杂任务。
- 核心机制:角色扮演与“思想实验” CAMEL 的设计初衷是探索 LLM 社会的“心智”。它通过一套精巧的提示机制(Inception Prompting),让两个或多个 Agent 在特定角色设定下自主对话,无需人工一步步指导。
-
双角色协作:典型的流程是设定一个 AI Assistant(执行者)和一个 AI User(需求方)。例如,User 扮演“想开发游戏的客户”,Assistant 扮演“资深程序员”,两者通过多轮对话自动拆解任务、讨论技术细节并生成代码。
-
任务自动细化:你只需提供一个粗略的目标(如“开发一个贪吃蛇游戏”),框架内的 Task Specifier 会自动将其细化为一系列具体的、可执行的子任务描述,然后交给角色 Agent 去执行。
第10章 多 Agent 框架——AutoGen 和 MetaGPT
AutoGen
AutoGen(由微软 Microsoft 开发)是一个强大的开源多智能体(Multi-Agent)对话框架,旨在构建基于 LLM 的复杂协作应用。与之前提到的 CAMEL 类似,它也强调“智能体之间的对话”,但它的核心突破在于原生支持“人机协同”和高度可配置的智能体拓扑。
MetaGPT