第一章(智能座舱概述)
智能座舱定义
智能座舱就是在传统车载座舱系统的基础上增加了智能化的属性,通过感知(语音、视觉等)、认知、决策、服务的过程使车辆能够主动服务驾驶员和乘客,提升座舱的科技感并带来更好的安全、便捷、趣味性体验.
对于消费者而言,座舱就是目光所及、耳朵所听、触觉所至的一切可以交互的内饰或零部件,包括座椅、灯光、空调、方向盘、车机、仪表、抬头显示仪(Head Up Display,HUD)等。
第二章(智能座舱技术架构及整体开发流程)
技术架构图
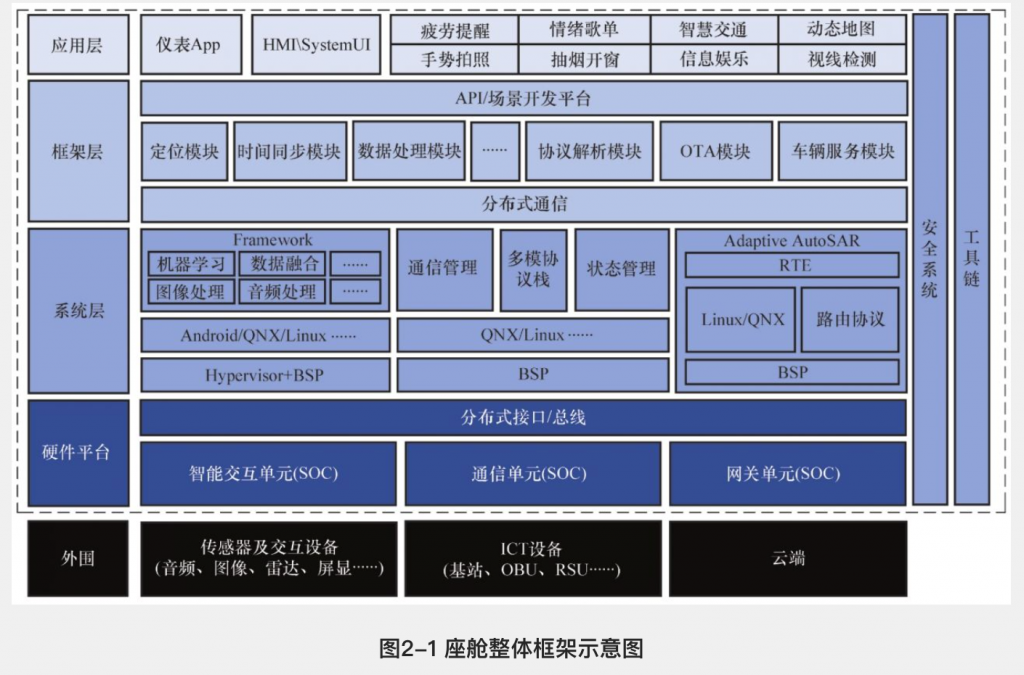
SOP的全称是Standard Operating Procedure,标准作业程式。
第三章(智能座舱硬件基础)
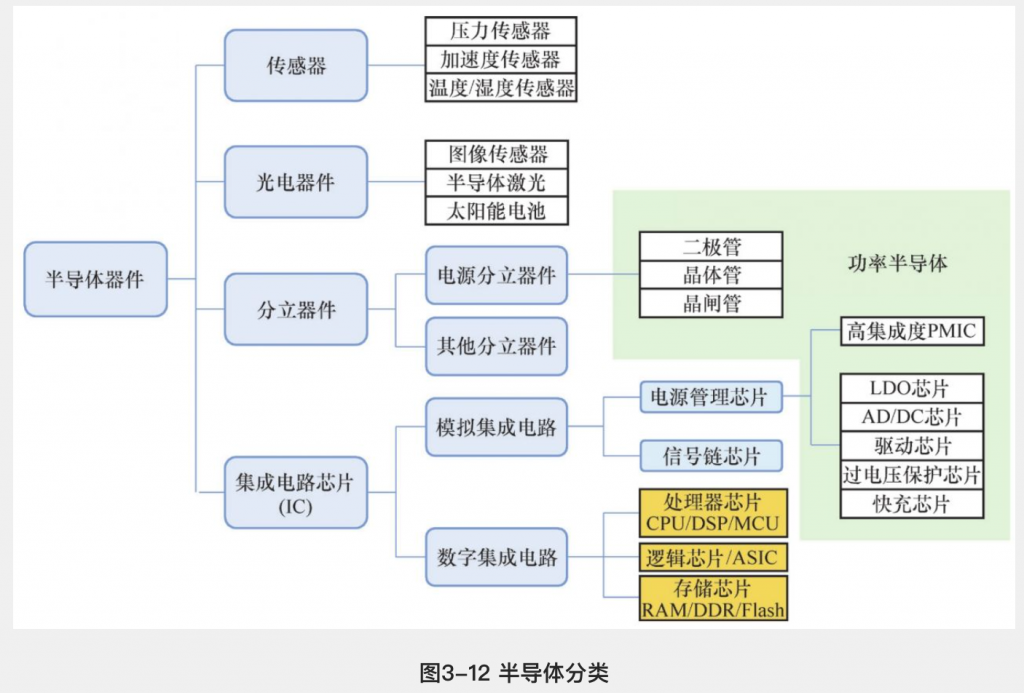
智能座舱是多种硬件技术及模块的集成,如芯片、各类传感器、屏幕、车内娱乐系统(音响、氛围灯等)
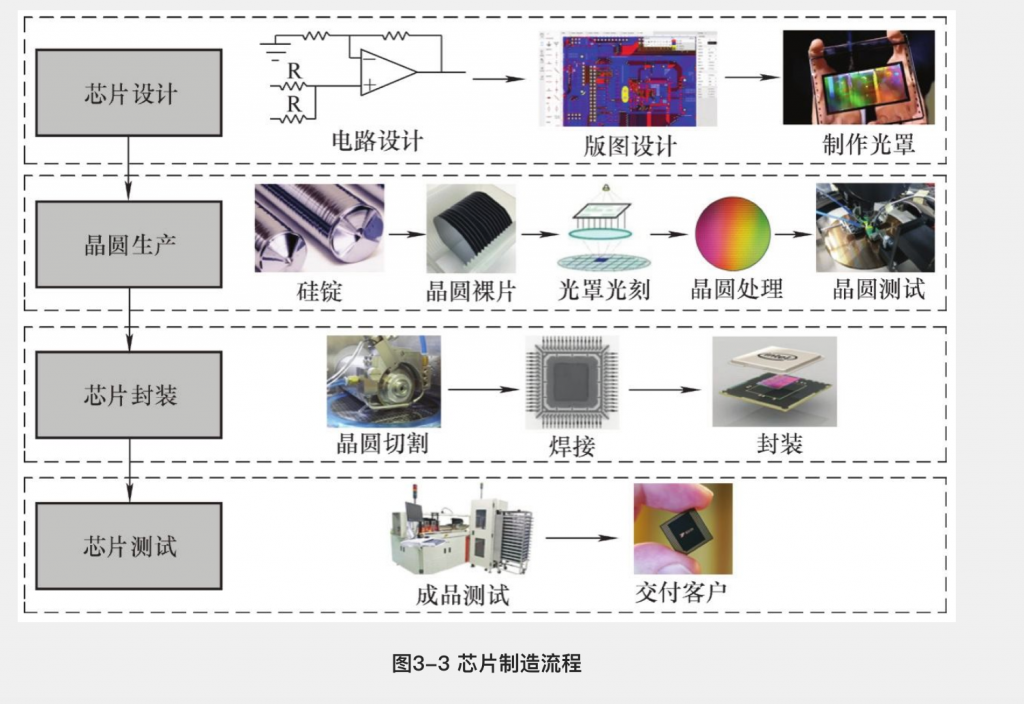
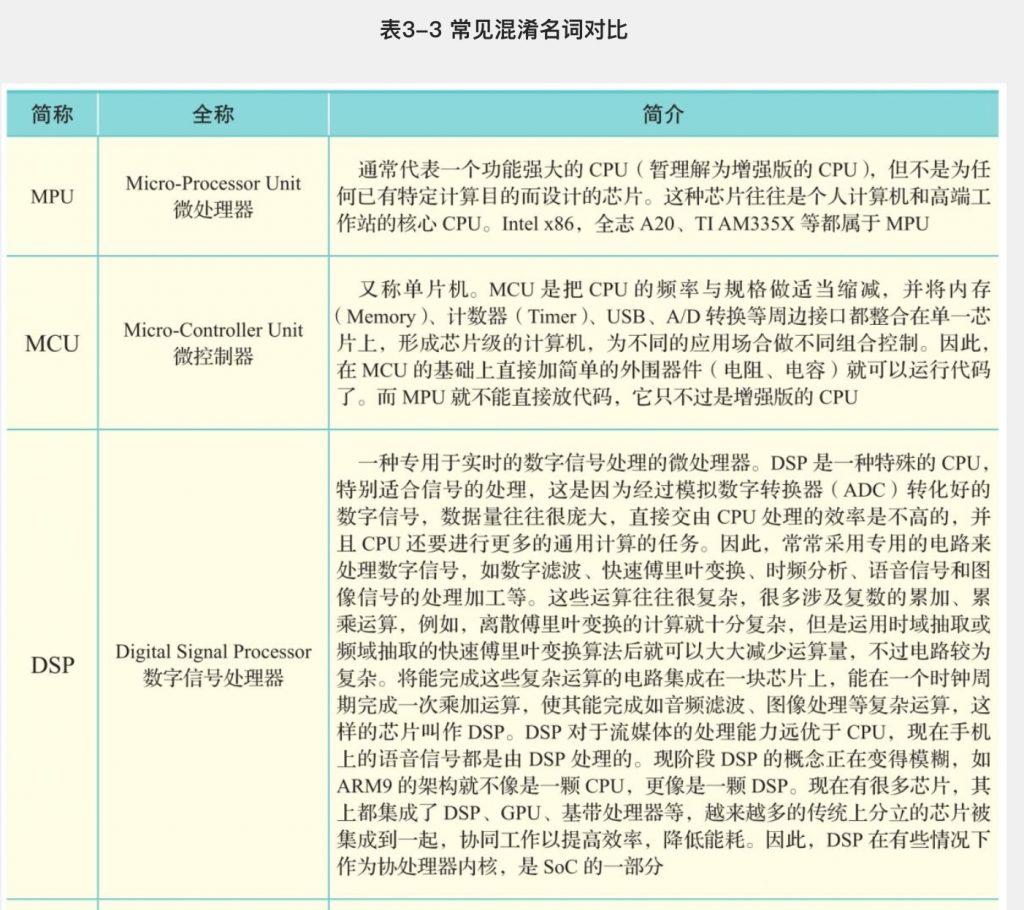
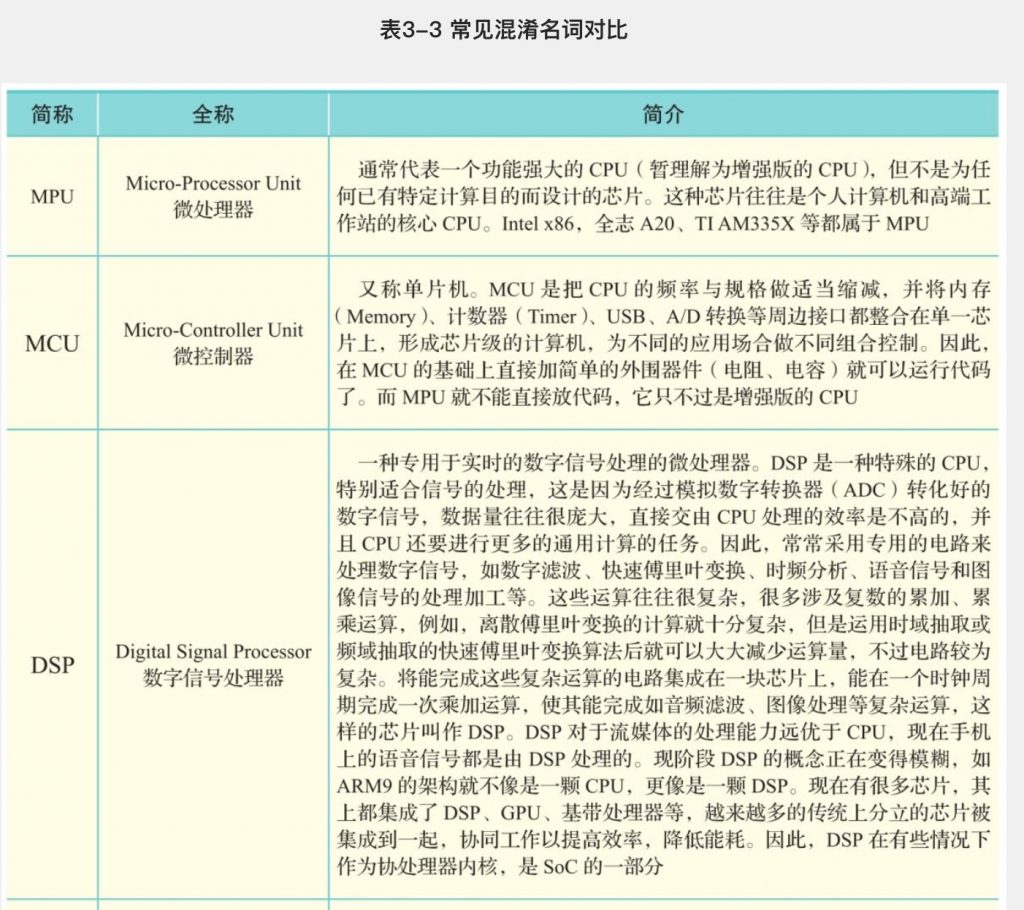
芯片
图形处理器

我们可以看到两者有相同之处,即两者都有总线和外界联系,有自己的缓存体系以及算数逻辑单 元。一句话,两者都为了完成计算任务而设计。然而它们的不同之处更加明显:①缓存体系上, CPU的缓存远大于GPU;②控制单元上,CPU拥有复杂的控制单元,而GPU的控制单元非常简 单;③算术逻辑单元上,CPU虽然有多核,但总数没有超过两位数。GPU的核数远超CPU,被称 为众核(NVIDIA Fermi有512个核)。因此CPU擅长处理具有复杂计算步骤和复杂数据依赖的计 算任务,如分布式计算、数据压缩、人工智能、物理模拟等。GPU擅长处理计算量大、复杂度 底、重复性高的大规模并发计算,如游戏中的大规模多边形运算、颜色渲染等。简而言之,当程 序员为CPU编写程序时,他们倾向于利用复杂的逻辑结构优化算法从而减少计算任务的运行时 间,即延迟(Latency)。当程序员为GPU编写程序时,则利用其处理海量数据的优势,通过提高 总的数据吞吐量(Throughput)来掩盖Lantency。
有了以上知识的铺垫,就容易理解为什么GPU适合做模型训练(Training)与推理(Inference)。 这是因为模型通常具有许多参数。例如,流行的VGG图像分类模型有16层,大约1.4亿个参数。 在运行推理时,需要将输入数据(如图像)传递到每个图层,通常将该数据乘以图层参数。在训 练期间,还必须稍微调整每个参数以更好地拟合数据,这是很大的计算量。GPU的多核结构刚好 可以同时并行完成以上的简单拟合运算,虽然单个核相对于CPU来说较慢,但在大规模的并行 下,依然比CPU的整体性能高出一个数量级。例如,Macbook拥有运行速度为3.1GHz且4个内核的 CPU,NVidia K80 GPU拥有近5000个内核,尽管单核运行速度要慢得多(562MHz,时钟速度大 约只有1/6),但是并行速度提高了1250倍。
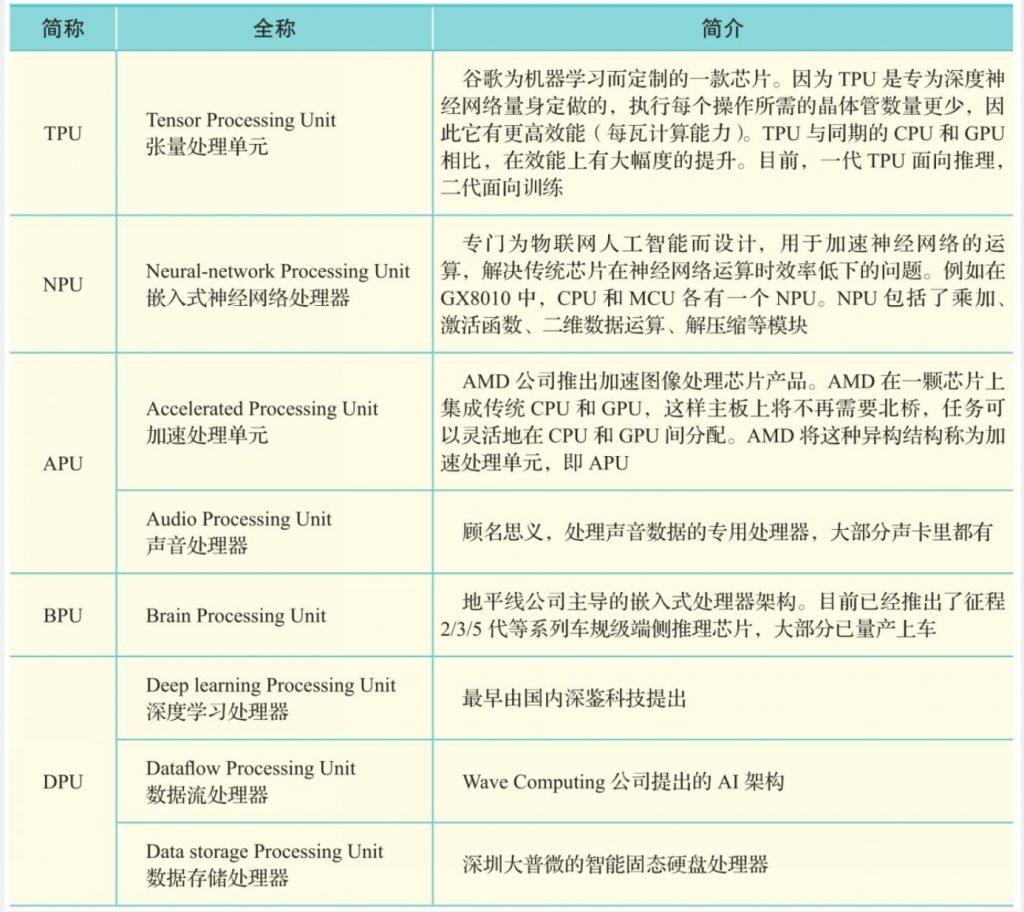
在现实场景中,GPU大部分在云端使用,而对于像座舱这样的端侧推理来说,往往需要更加小型 化、低功耗的芯片来做网络模型推理。随着深度学习(Deep Learning)技术的深入研究与广泛应 用,做AI芯片的公司也越来越多,很多公司都采用了“xPU”的命名方式,因此名字非常相似,表 3-2对其加以区分并做简要介绍。需要注意的是,大部分缩写可能有多个来源,这里只选取和芯片 相关的含义

片上系统(System on Chip,SoC)
可以看到,每颗芯片都有一定的功能,将它们组合在一起才是一个电路。随着半导体技术的发 展,大家发现即使每个功能的芯片集成度会变高变复杂,但每个独立功能的芯片所构成的电路依 然会很占面积且经济性较差,所以就出现了SoC,将上述特定功能的器件在一颗芯片上实现。如 图3-13所示,在SoC出现之前,可编程核、IP、定制逻辑、存储器等都在一个PCB上。这些分离的 芯片需要通过PCB进行互联,其可靠性、功耗以及效率等方面均不是最优。后来随着半导体工艺 技术的发展,SoC技术将上面这些芯片的功能完全做在一颗芯片上,而集成度变高会让整个性价 比和可靠性也变高。这是因为在SoC中是完全基于芯片内部总线的互联,会让可靠性和功耗等各 方面变得最优。在设计层面,SoC有两个显著的特点:①硬件规模庞大,通常基于IP设计模式; ②软件比重大,需要进行软硬件协同设计。由于SoC可以充分利用已有的设计积累,显著地提高 了ASIC的设计能力。SoC在性能、成本、功耗、可靠性,以及生命周期与适用范围各方面都有明 显的优势,它是集成电路设计发展的必然趋势。
SoC强调的是一个整体,用“麻雀虽小五脏俱全”来形容它再确切不过了。
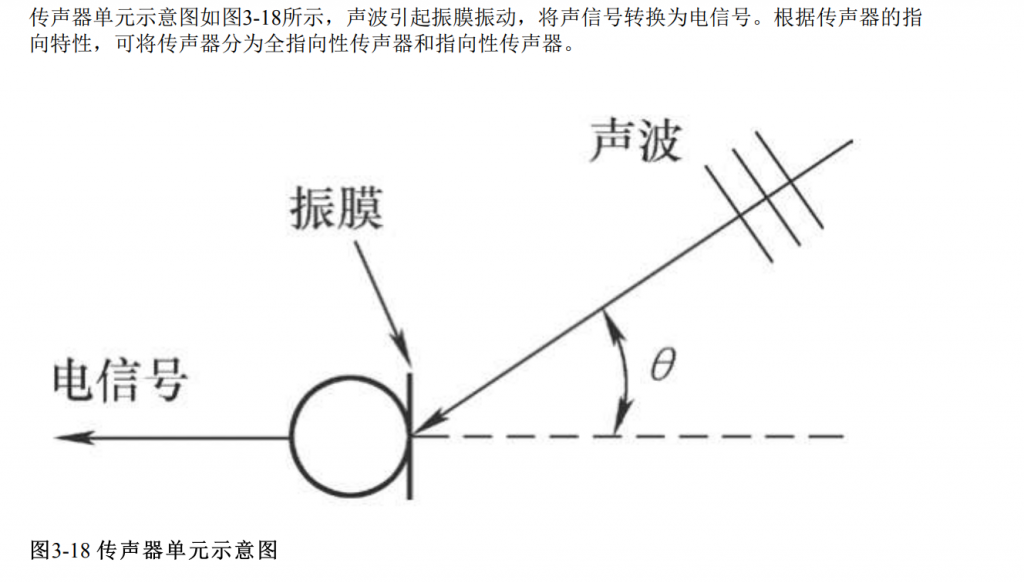
车载传声器
基于语音的车载人机交互系统在智能座舱领域占据重 要地位,车载传声器阵列已成为智能汽车的标配。传声器阵列是指由2个及以上的传声器单元, 以一定的空间结构组成的声学系统,配合高效的语音信号处理算法,可以实现回声消除、声源定 位、语音分离和噪声抑制等任务。
车载多音区的实现方式
传声器通过车机接入,经过ADC连接到车机DSP,在DSP内部将原始的传声器信号和参考 信号经过降采样、数据排列,以TDM8、16kHz、16bit的方式通过I2S接口传给J3,J3接收到音频 信号之后,会利用CPU和BPU高效的算力进行语音信号的处理,包括语音降噪、回声消除、盲源 分离,自动增益等。通过图像和语音的同时接入,进行多模态的融合,可以实现更丰富的功能场 景,提升用户的实际体验。
第四章(智能座舱算法基础)
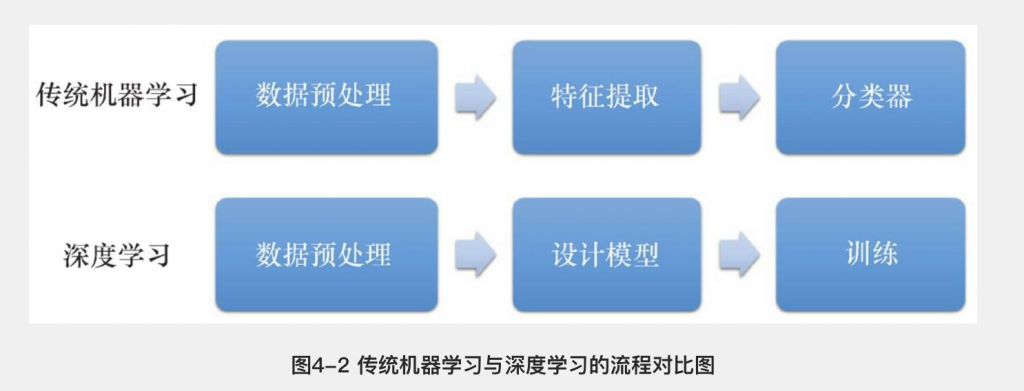
深度学习算法通常由三 部分组成,包括神经网络模型、损失函数和优化方式。深度神经网络模型本质上就是一个复杂的 函数,这个函数将输入映射到输出值,该函数是由许多个简单函数复合而成.
卷积神经网络
卷积神经网络在计算机视觉中应用广泛,常见的应用任务为图像分类识别、目标检测追踪、图像分割等.广泛被使用的CNN模型有VGG、ResNet、DenseNet、MobileNet、ResNeXt等.
机器视觉
语音识别
自动语音识别(Automatic Speech Recognition, ASR),简称语音识别,是重要组成部分

声学模型
人耳接收到声音后,经过神经传导到大脑分析判断声音类型,并进一步分辨可能的发音内容。人 的大脑从出生开始就不断在学习外界的声音,经过长时间潜移默化的训练,最终才听懂人类的语 言。机器和人一样,也需要学习语言的共性和发音的规律,建立起语音信号的声学模型 (Acoustic Model,AM),才能进行语音识别。声学模型是语音识别系统中最为重要的模块之 一。声学建模包含建模单元选取、模型状态聚类、模型参数估计等很多方面。
声学建模单元的选择可以采用多种方案,比如采用音节建模、音素建模或者声韵母建模等。
声学模型主要有三种:基于GMM-HMM的声学模型、基于DNN-HMM的声学模型以及端到端模型
语言模型
主流语言模型一般采用基于统计的方法,通常是概率模型。计算机借助于模型参 数,可以估计出自然语言中每个句子出现的可能性。统计语言模型采用语料库训练得到,强调语 料库是语言知识的源泉,通过对语料库进行深层加工、统计和学习,获取自然语言文本中的语言 学知识,从而可以客观地描述大规模真实文本中细微的语言现象。
1.N-gram 模型
N -gram统计语言模型由于其构建简单、容易理解等优点在很多领域得以广泛应用。 N -gram语言 模型以马尔可夫假设为前提,句子中第 i 个词出现的概率只与前 N -1个词有关,而与其他词无 关。
2.基于神经网络的语言模型
N -gram语言模型有个显著的特点,对于未在训练语料中出现的单词,其概率值为0,这与实际情 况不符。另外,虽然使用平滑技术的 N -gram语言模型能够正常工作,但维度灾难问题大大制约 了语言模型在大规模语料库上的建模能力。当人们想要对离散空间中的联合分布建模时,这个问 题极其明显。例如,当你想要建模一个10000词汇的 N -gram语言模型时,便需要10000 n -1个参 数。神经网络能学习到观察值在连续空间的特征表征,为了解决维度灾难问题,人们希望神经网 络能够应用于语言模型,以适配自然语言的离散、组合和稀疏特性。
三种常见的语言模型:前馈神经网络语言模型、循环神经网络语言模型以及长短期记忆的循环神经网络语言模型。
解码器
语音识别的最终目的是在由各种可能的单词序列构成的搜索空间中,寻找最优的单词序列。这在 本质上属于搜索算法或解码算法的范畴,即解码器要完成的任务。
语音识别案例
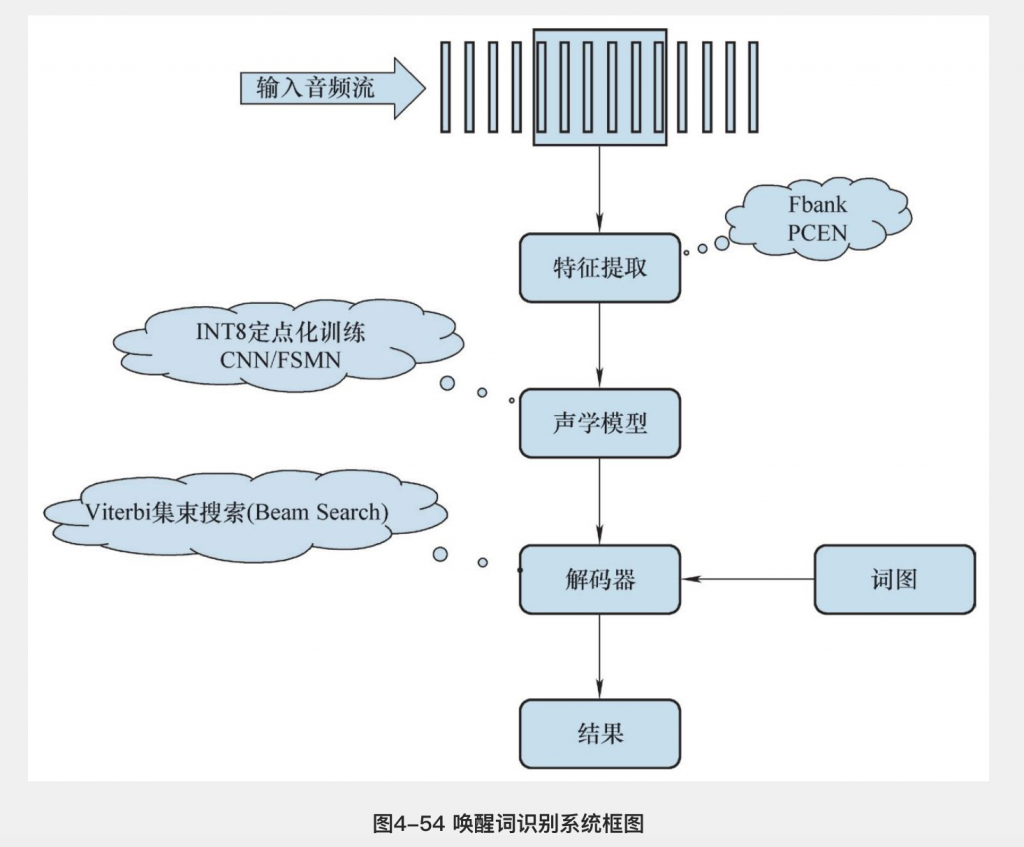
首先根据输入的vad信息截取有效语音部分,对语音提取声学特征,一般采用40维Fbank特征加上 一阶二阶差分。然后,将声学特征输入唤醒词训练的声学模型中,计算声学打分。最后,在由唤醒词和垃圾吸收网络构成的搜索空间上,根据声学打分结果进行Viterbi解码,得到识别结果,判断唤醒还是拒识。